Tinkerings
My notes to build mental models for how things work.
Triton Kernels
Modern GPUs have massive compute but limited memory bandwidth. The key metric is
arithmetic intensity (AI)
:
Sep 8, 2025
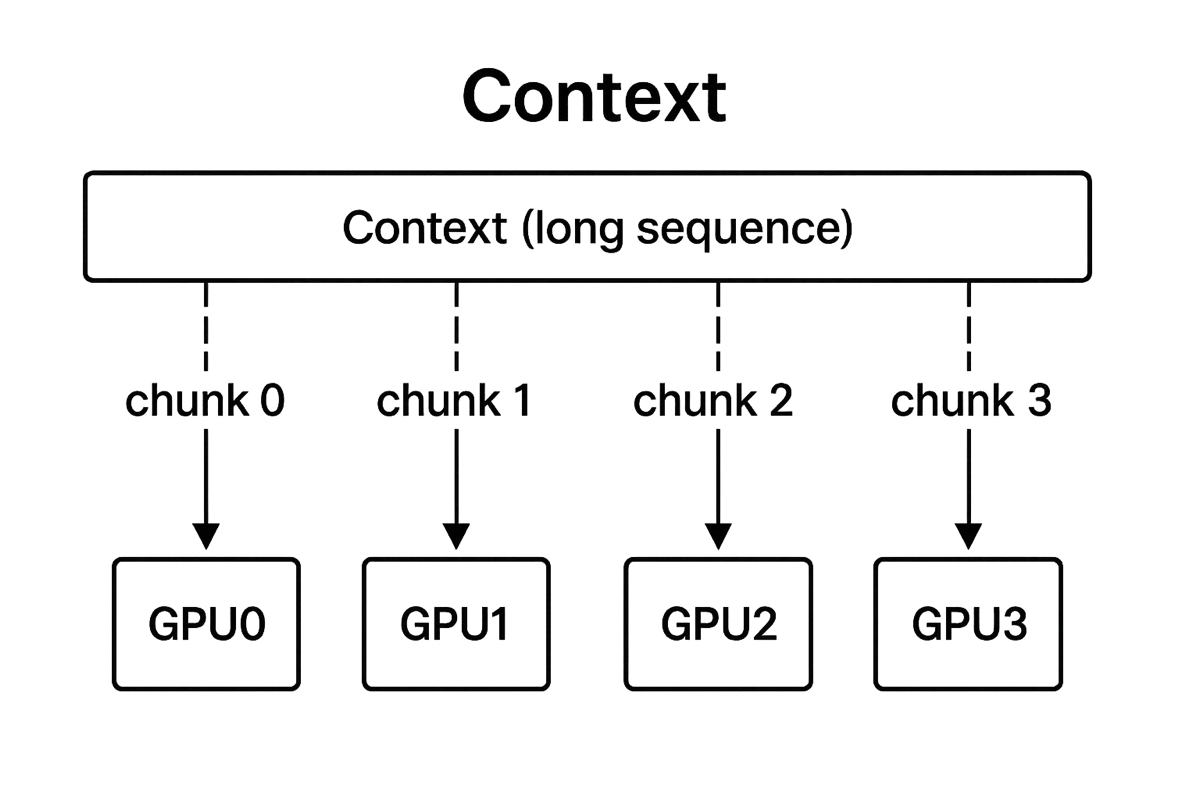
Context Parallelism
Context Parallelism (CP) is a distributed training technique that enables training of LLMs with extremely long sequences (up to 1M tokens) by sharding the sequence dimension…
Sep 3, 2025
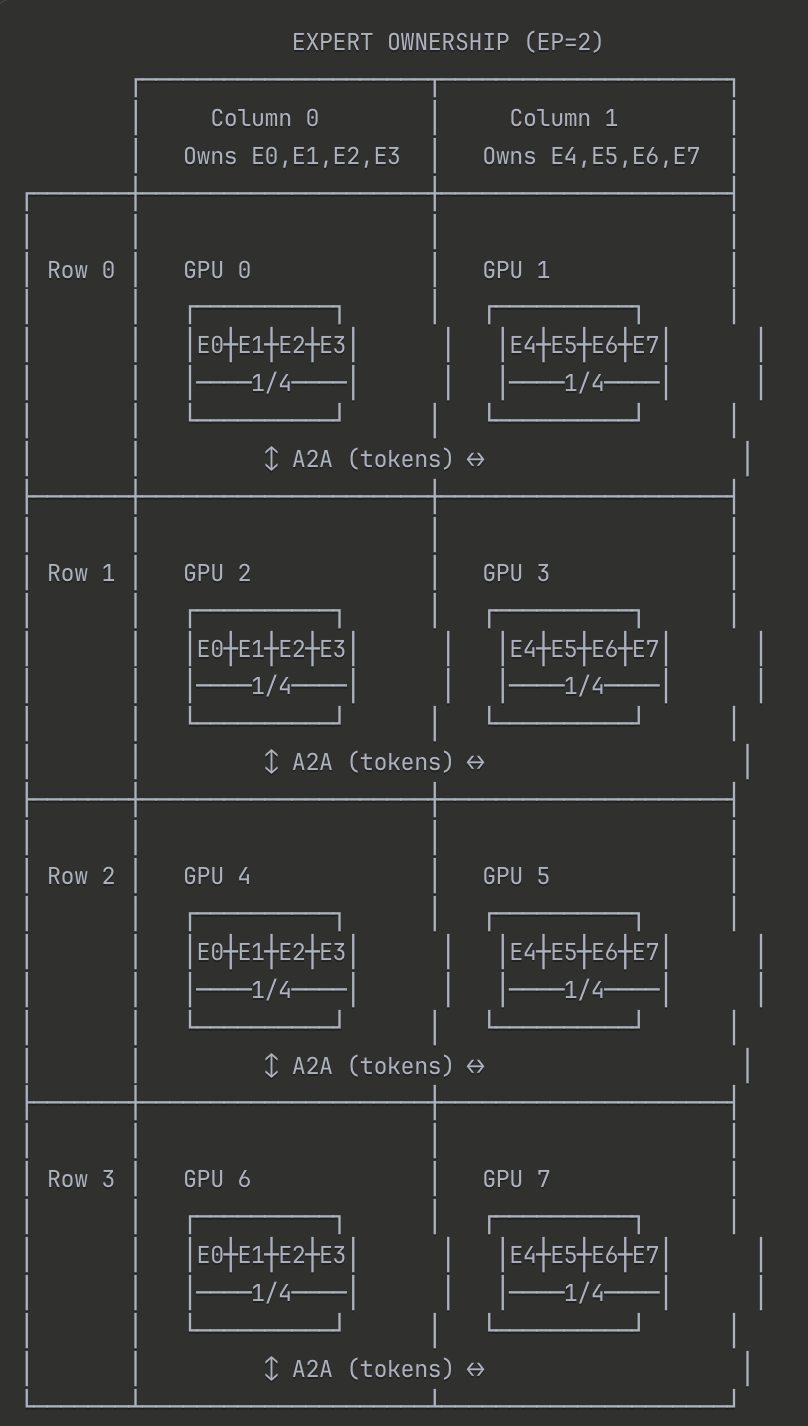
Expert Parallelism
Let’s distill how to run a Mixture-of-Experts (MoE) model with expert parallelism with an example.
Sep 1, 2025
No matching items